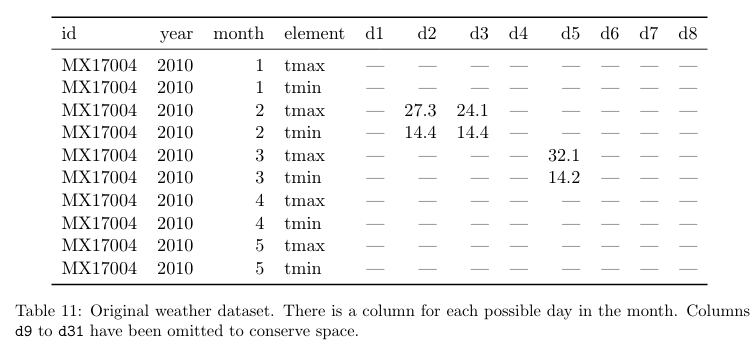
A particularly messy structural issue occurs when a dataset has variable names in both columns and rows. For example, a dataset with an field/column for each day of the month (on the horizontal) and a row title for 'month' (on the vertical). This situation occurs most often when the data provided comes in the form of and cross-tabulated aggregate data.
Table 11 shows daily weather data from the Global Historical Climatology Networkfor one weather station (MX17004) in Mexico for five months in 2010. It has variables in individual columns (id,year,month), spread across columns (day, d1-d31) and across rows(tmin,tmax) (minimum and maximum temperature).