Data Restructuring
To address issues of structure discovered during Data Profiling, it often necessary to restructure the provided dataset into multiple new datasets that are more easily analyzed. This activity can be thought of as being akin to the process of database normalization, the process of organizing the columns (attributes) and tables (relations) of a relational database to minimize data redundancy (thus achieving Codd’s 3rd Normal Form - [Codd, E. F. “Recent Investigations into Relational Data Base Systems”. IBM Research Report RJ1385 (April 23, 1974). Republished in Proc. 1974 Congress (Stockholm, Sweden, 1974). , N.Y.: North-Holland (1974).]
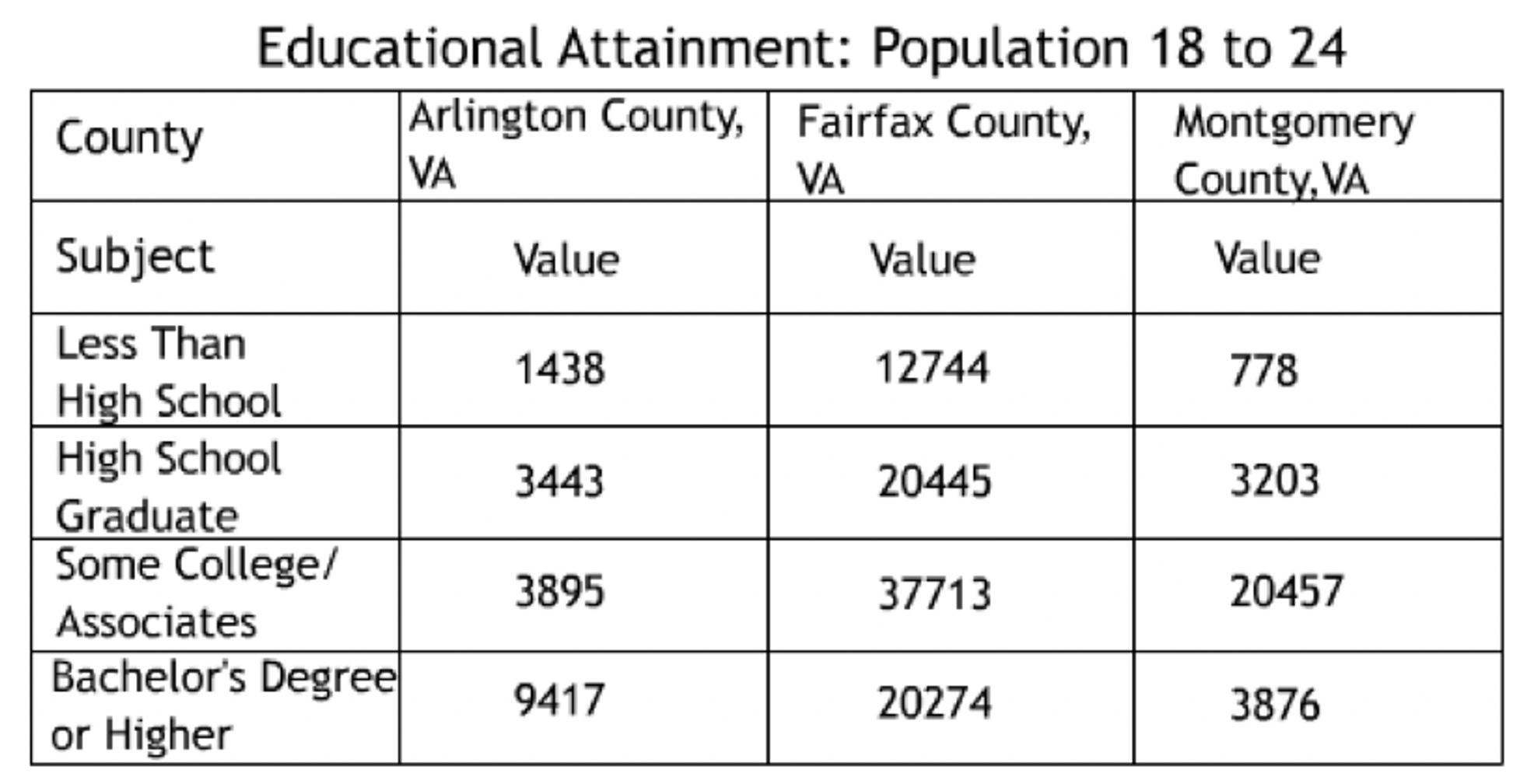
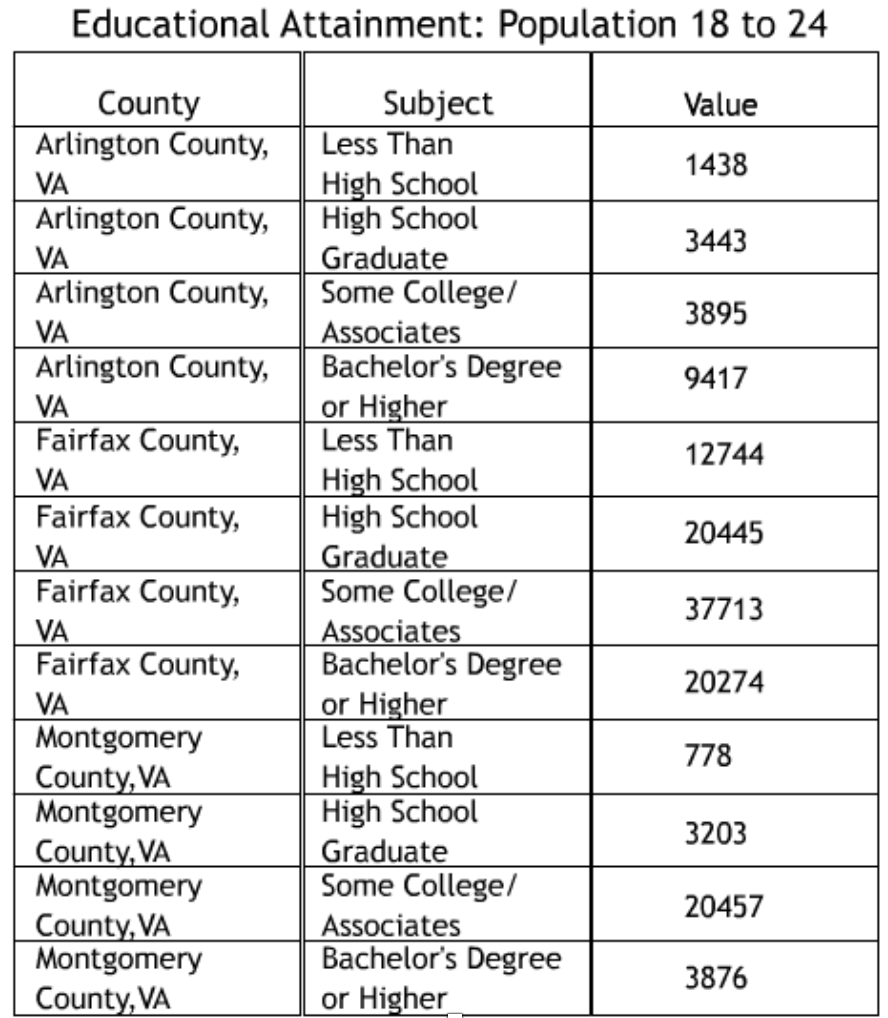
An example of restructuring in the education case study was the necessary sub-setting of the Fall Membership database into 3 tables to account for student’s race, gender, and disadvantaged status. Each of the 3 tables were aggregated by school year, division number, and grade code according to a set of rules determining inclusion/exclusion of each variable in the Fall Membership table.
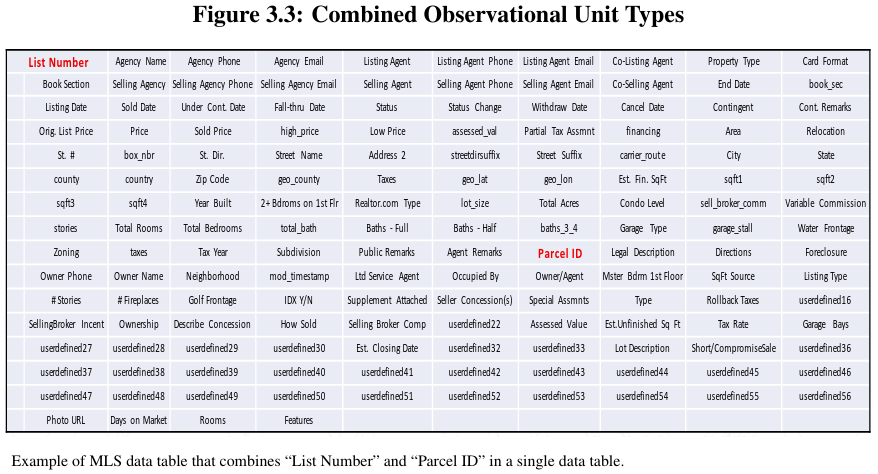
Another example of necessary restructuring occurred when dealing with 3rd-party provided MLS data (as discussed in a few examples above). In this case, it was necessary to divide the provided dataset into multiple separate datasets, Property ID \& Location, Property Characteristics, Property Sales Information, and Property Tax Information. Each of these new datasets represents a distinct unit of analysis. All of the new datasets are then associated via a new identifier, in this case, Parcel Id (see Figure \ref{MLSRestructure}). However, “Parcel ID” in this case has been left blank in over 7% of the entries. Therefore, extra work was required employing the use of a geocoding API to locate a property within county parcel maps that already include a Parcel ID. In addition, an additional complication is the fact that no standardized address format was used in the creation of the MLS record. Therefore, a small amount of direct interaction and decision making by an analyst was also necessary to finalize the geographic matching.
Restructuring single MLS dataset into multiple associated datasets.
Starting with:
Restructuring to:
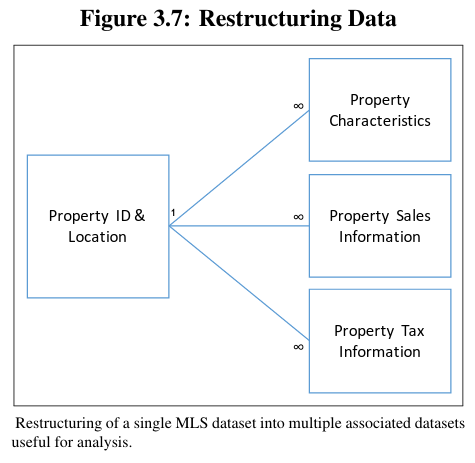
Divided Observational Type
And restructuring:
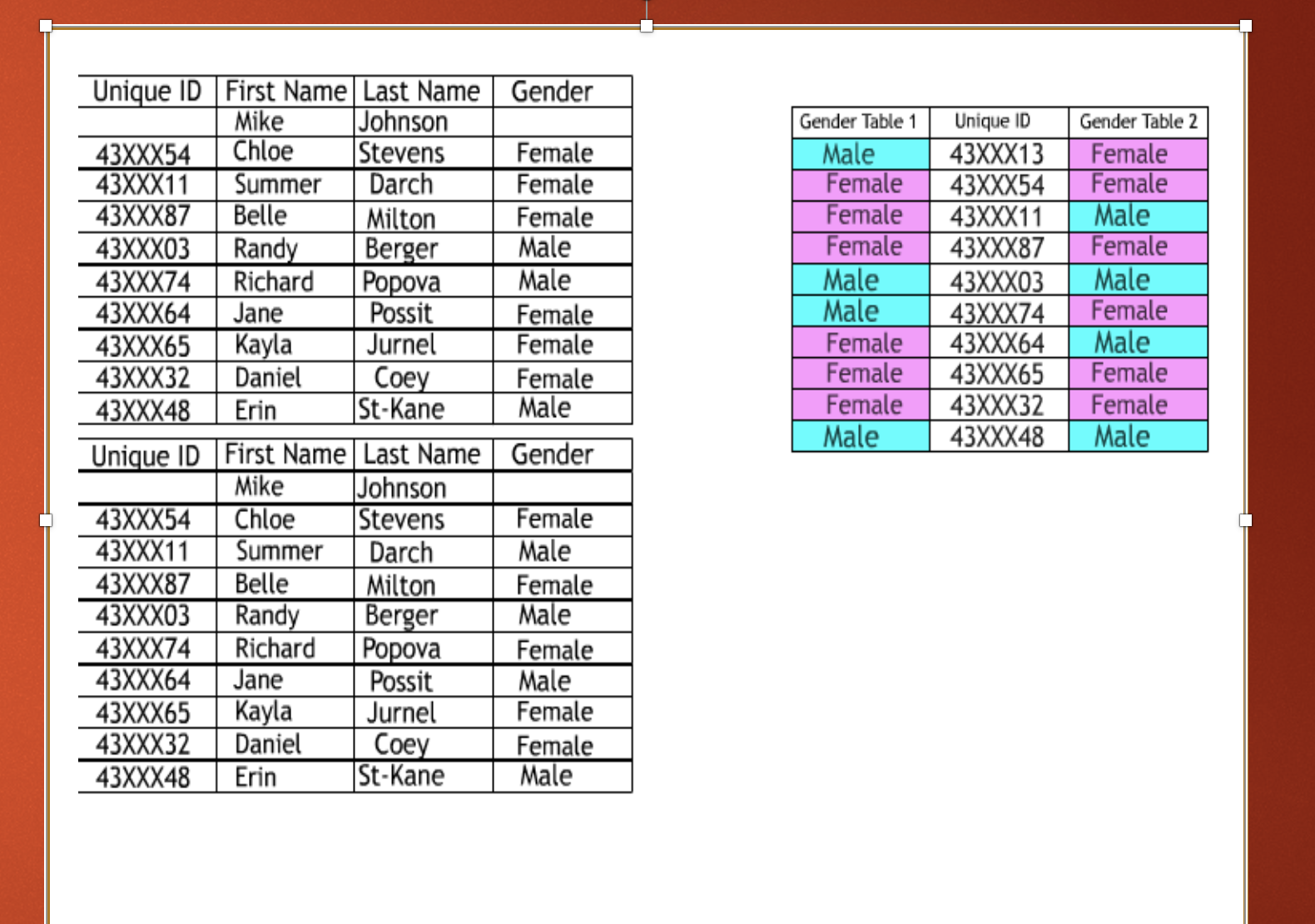
Multiple Observation Directions