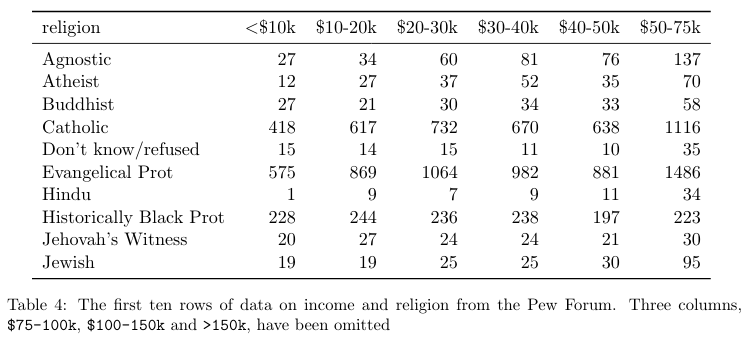
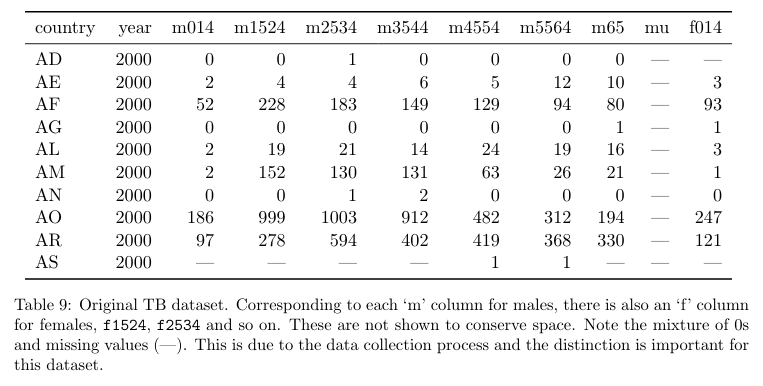
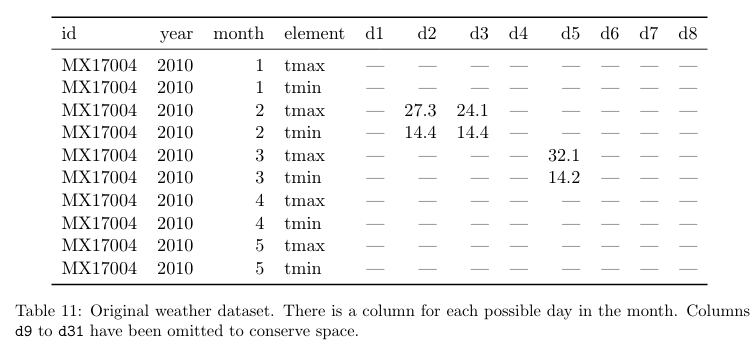
'Missing variables' means that a dataset has values in column headers instead of variable names. It is not uncommon to receive tabular datasets that have been designed for the purpose of presentation, not analysis, where variables form both the rows and columns, and column headers are values, not variable names. While this type of structural issue was not experienced with the datasets under consideration, it is an issue to be cognizant of, especially, as our experience indicates, when dealing with agency datasets released as tabular data in spreadsheet files. Such files are often initially produced for the purpose of conveying aggregated summary data to decision-makers and are not constructed like a traditional dataset (i.e. one record per row with clear field/column titles).
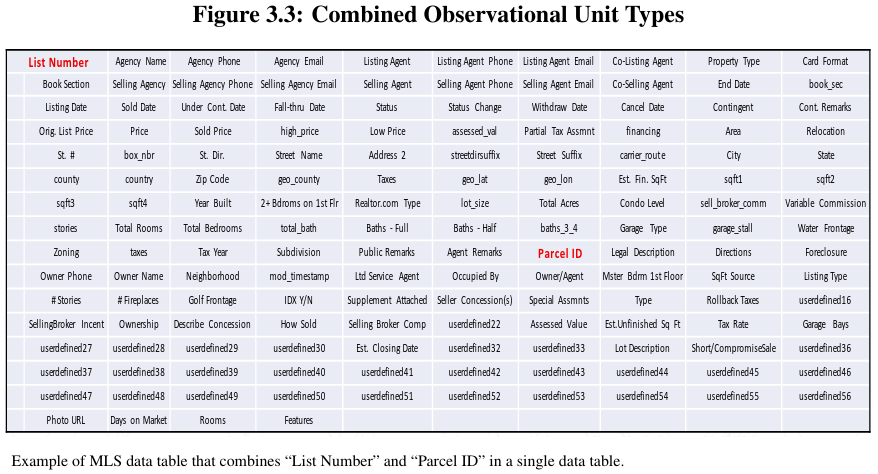
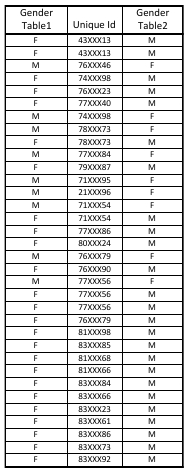 Example of divided observational units for gender mismatched in multiple tables.
Example of divided observational units for gender mismatched in multiple tables.