Record Consistency
The concept of record consistency is best understood as the degree of logical agreement “between” record field values in either a single dataset or between two or more datasets. When there is an expected logical relationship between two or more entities, we can refer to the rule specificying this logic as a type of relationship validation called a dependency constraint. Therefore, consistency becomes the degree to which these attributes satisfy said dependency constraint. An example of a logical requirement is that fields A and B must sum to field C. Logical requirements may be quite involved. For example, ‘A has two children’, ‘A is B’s father’, ‘A is C’s father’, and ‘A is D’s father’ are inconsistent.
A simple example of a record inconsistency would be a location disagreement like a zip-code that does not agree with a state code. Another might be the identification of a male who is also pregnant.
A more complex example would involve consistency validation of fields associated with student withdrawal in education records. For example, most education records contain some form of an ‘active code’ categorizing the student’s current form of interaction with the educational system. Most systems will have a code for ‘Inactive’ and/or ‘Not enrolled’. Most systems will also have a field for withdrawal date. If a student has been categorized as ‘Inactive’ or ‘Not enrolled’ but does not have an entry for withdrawal date, then there exists a record consistency issue.
Checking for records with inconsistent relationship between active_status and exit_code and exit_date
SELECT unique_id, school_year, division_number__serving_school_number
FROM student_mobility_fields_2005_2015
WHERE active_status = 'I'
AND exit_code IS NULL AND exit_date IS NULL
Longitudinal Consistency
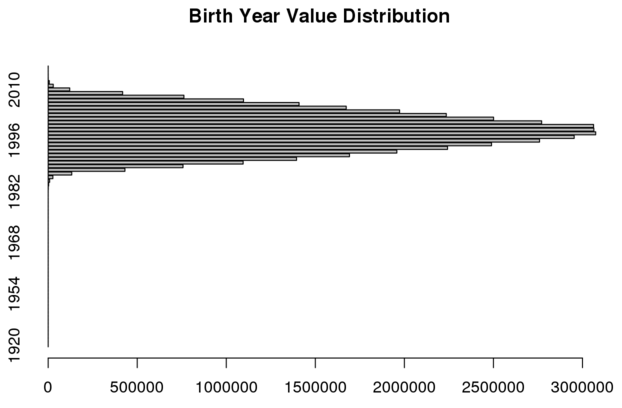
An inconsistency in the data when checked over time (longitudinally), to see if the same value is recorded for every new record when it should be (i.e. birthdate and other demographics).
Causes of longitudinal inconsistency are varied, but a common source of inconsistency comes from situations where locally derived information is provided with no associated master list or file. An exhaustive ‘master list’ of individuals receiving a public service are, in fact, quite rare. In our study, this occurred with student records such as from the Virginia Department of Education (VDOE). Here the student demographics occur in multiple records about the same student recorded in the same year. Truth must be derived from the multiple observations. For example, the VDOE data we found 16,310 of the 2,346,058 individuals to have more than one value for gender.
A simple consistency check on the field ‘gender’ (in pseudo-code) would look like:
count students
from student_records joined to itself on student\_id
where gender does not match
A consistently troublesome demographic variable, from a longitudinal consistency viewpoint, is race. Race categorization schemes change fairy frequently (in comparison to other demographic categories). In addition, people will periodically elect to change the racial category with which the identify.
A lonitudinal consistency check of race in the Virginia Student Record Collection:
SELECT distinct a.unique_id
FROM student_mobility_fields_2005_2015 a
JOIN student_mobility_fields_2005_2015 b
ON a.unique_id = b.unique_id
WHERE a.race_type <> b.race_type
## [1] 160055
In the Virginia Student Record Collection there are 160055 such inconsistencies. This means the dataset is about .37% inconsistent (which actually means it is still a pretty good variable for many uses).
 A considerable amount of data quality research involves investigating and describing various categories
of desirable attributes (or dimensions) of data. These lists commonly include accuracy, correctness,
currency, completeness and relevance, as described in Chapter 2. Nearly 200 such terms have been
identified and there is little agreement in their nature (are these concepts, goals or criteria?),
their definitions or measures (Wang et al., 1993). Here we have let a typology
emerge form the project data work. This typology consists of five data quality areas: completeness,
value validity, consistency, uniqueness, and duplication. Regardless the typology chosen,
the final judgment of data quality is measured by adherence of a dataset to a set of data quality rules.
Like data quality attributes, these rules can take one of several forms.
Here we choose a typology consisting of three rule-types employed by the DoD in its data quality management
efforts. These are: null constraint rules, domain validation rules,
and relationship validation rules. Code is developed to enforce these rules. For our study,
examples are given in psuedo-code:
A considerable amount of data quality research involves investigating and describing various categories
of desirable attributes (or dimensions) of data. These lists commonly include accuracy, correctness,
currency, completeness and relevance, as described in Chapter 2. Nearly 200 such terms have been
identified and there is little agreement in their nature (are these concepts, goals or criteria?),
their definitions or measures (Wang et al., 1993). Here we have let a typology
emerge form the project data work. This typology consists of five data quality areas: completeness,
value validity, consistency, uniqueness, and duplication. Regardless the typology chosen,
the final judgment of data quality is measured by adherence of a dataset to a set of data quality rules.
Like data quality attributes, these rules can take one of several forms.
Here we choose a typology consisting of three rule-types employed by the DoD in its data quality management
efforts. These are: null constraint rules, domain validation rules,
and relationship validation rules. Code is developed to enforce these rules. For our study,
examples are given in psuedo-code: